Amazon Web Services announced Wednesday that its Amazon SageMaker Ground Truth helps build highly accurate training datasets for machine learning (ML) quickly. Ground Truth offers easy access to third-party and own human labelers, and provides them with built-in workflows and interfaces for common labeling tasks.
Additionally, Ground Truth can lower labeling costs by up to 70 percent using automatic labeling, which works by training Ground Truth from data humans have labeled so that the service learns to label data independently.
Amazon SageMaker Ground Truth helps users build highly accurate training datasets for machine learning quickly. SageMaker Ground Truth offers easy access to public and private human labelers and provides them with built-in workflows and interfaces for common labeling tasks. Additionally, SageMaker Ground Truth can lower labeling costs by up to 70 percent using automatic labeling, which works by training Ground Truth from data labeled by humans so that the service learns to label data independently.
Successful machine learning models are built on the shoulders of large volumes of high-quality training data. But, the process to create the training data necessary to build these models is often expensive, complicated, and time-consuming. The majority of models created today require a human to manually label data in a way that allows the model to learn how to make correct decisions.
For example, building a computer vision system that is reliable enough to identify objects - such as traffic lights, stop signs, and pedestrians - requires thousands of hours of video recordings that consist of hundreds of millions of video frames. Each one of these frames needs all of the important elements like the road, other cars, and signage to be labeled by a human before any work can begin on the model that the user wants to develop.
Amazon SageMaker Ground Truth reduces the time and effort required to create datasets for training to reduce costs. These savings are achieved by using machine learning to automatically label data. The model is able to get progressively better over time by continuously learning from labels created by human labelers.
Where the labeling model has high confidence in its results based on what it has learned so far, it will automatically apply labels to the raw data. Where the labeling model has lower confidence in its results, it will pass the data to humans to do the labeling.
The human-generated labels are provided back to the labeling model for it to learn from and improve. Over time, SageMaker Ground Truth can label more and more data automatically and substantially speed up the creation of training datasets.

Semantic segmentation is a computer vision ML technique that involves assigning class labels to individual pixels in an image. For example, in video frames captured by a moving vehicle, class labels can include vehicles, pedestrians, roads, traffic signals, buildings, or backgrounds. It provides a high-precision understanding of the locations of different objects in the image and is often used to build perception systems for autonomous vehicles or robotics.
To build an ML model for semantic segmentation, it is first necessary to label a large volume of data at the pixel level. This labeling process is complex. It requires skilled labelers and significant time—some images can take up to two hours to label accurately.
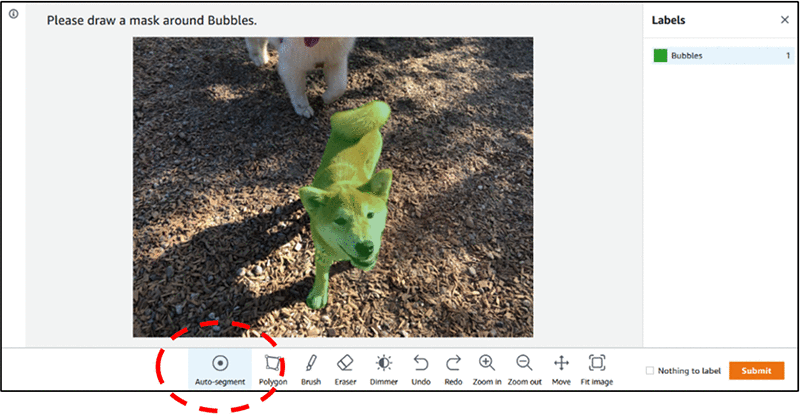
To increase labeling throughput, improve accuracy, and mitigate labeler fatigue, Ground Truth added the auto-segment feature to the semantic segmentation labeling user interface. The auto-segment tool simplifies the task by automatically labeling areas of interest in an image with only minimal input.
Users can accept, undo, or correct the resulting output from auto-segment. The screenshot highlights the auto-segmenting feature in the toolbar, and shows that it captured the dog in the image as an object.
With this new feature, users can work up to ten times faster on semantic segmentation tasks. Instead of drawing a tightly fitting polygon or using the brush tool to capture an object in an image, users draw four points: one at the top-most, bottom-most, left-most, and right-most points of the object. Ground Truth takes these four points as input and uses the Deep Extreme Cut (DEXTR) algorithm to produce a tightly fitting mask around the object.









No comments:
Post a Comment